人工智能基准性能测试:开工晴雨表

人工智能催生了意图在吞吐量、延迟和功耗之间取得平衡的新一代芯片。
诸如 GPU、FPGA 和视觉处理单元 (VPU) 之类的人工智能加速器经过优化,可以计算神经网络工作负载。这些处理器架构为诸如计算机视觉 (CV)、语音识别和自然语言处理之类的应用提供了支持,还在物联网边缘设备上实现了本地人工智能推断。
但基准性能测试表明,这些加速器的性能表现并不均衡。选择一个加速器可能会对系统吞吐量、延迟、功耗和总体成本产生严重影响。
了解人工智能推断
准确了解什么是神经网络及相关计算要求至关重要。这将有助于澄清稍后审阅的基准性能测试。
神经网络是模仿人类大脑的人工智能技术的子集。神经网络不是单个算法,通常是多个分层软件算法的集合,就像一块蛋糕。
每一层都会分析输入数据集,并根据在训练阶段学到的特征对其进行分类。一层对某个特征进行分类后,将分类结果传递到下一层。在卷积神经网络 (CNN) 中,执行一次或多次线性数学运算(卷积)可生成多层累积表达式。
例如,在图像分类中,将为网络提供一张图片。一层会将形状分类为面部。另一层分辨出四肢。第三层分辨出毛皮。应用卷积后,神经网络最终得出结论,它是一只猫的图像(图 1)。这个过程称为推断。
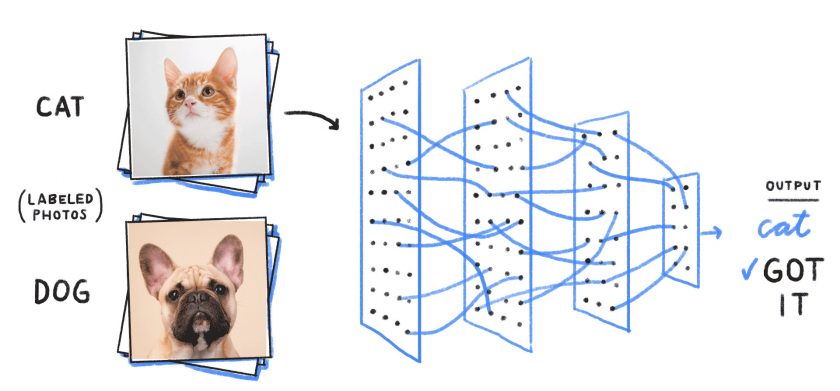
每次计算新层时,神经网络处理器都必须访问来自内存的输入数据。这就需要权衡利弊。
神经网络分层和卷积越多,人工智能加速器对于性能和高带宽内存访问的要求就越高。但您也可以通过降低准确性来升速,或者通过降速来降低功耗。这都取决于应用的需求。
GPU、FPGA、VPU 横向对比
吞吐量和延迟基准性能测试揭示了英特尔® Arria® 10 FPGA、英特尔® Movidius™ Myriad™ X VPU 和 NVIDIA Tesla GPU 在运行四个紧凑型图像分类神经网络时的性能表现。这四个网络是 GoogLeNetv1、ResNet-18、SqueezeNetv1.1 和 ResNet-50。
每个处理器都位于用于现实环境的现成加速卡中:
Arria 10 FPGA — 该软件定义的可编程逻辑器件具有高达每秒 1.5 万亿次浮点运算 (TFLOPS) 的功能,并且集成了 DSP 模块。这是 IEI Integration Corp. Mustang F100-A10 人工智能加速器卡在我们的基准性能测试中的表现。
Mustang F100-A10 采用了 8 GB 2400 MHz DDR4 内存和 PCIe Gen 3 x8 接口。这些功能支持在 20 多个同步视频通道上进行神经网络推断(图 2)。

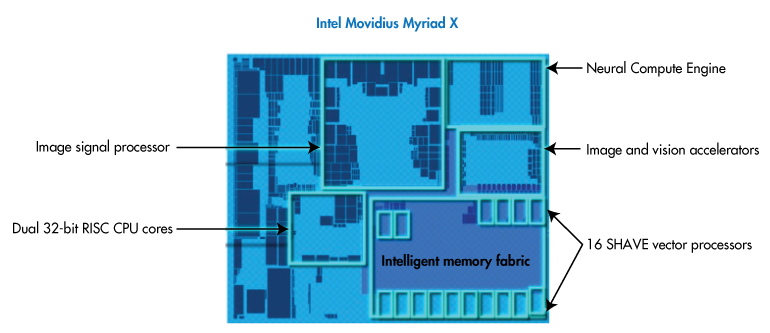
Myriad X VPU — 这些硬件加速器集成了神经计算引擎、16 个可编程 SHAVE 内核、超高吞吐量内存结构以及支持多达 8 个高清摄像头传感器的 4K 图像信号处理 (ISP) 管道。这些指标作为 IEI Mustang-V100-MX8 的一部分包括在基准性能测试中。
Mustang-V100-MX8 集成了 8 个 Movidius X VPU,能够同时针对多个视觉管道执行神经网络算法(图 3)。每个 VPU 消耗的功率仅为 2.5 瓦。

NVIDIA Tesla GPU — 这些推断加速器基于 NVIDIA Pascal 架构,提供 5.5 TFLOPS 的性能,延迟仅相当于 CPU 的十五分之一。NVIDIA P4 Hyperscale Inferencing Platform 是基准性能测试的参照对象。
图 4 显示了基准性能测试结果。吞吐量以每秒分析的图像数表示,而延迟表示分析每个图像所需的时间(用毫秒表示)。
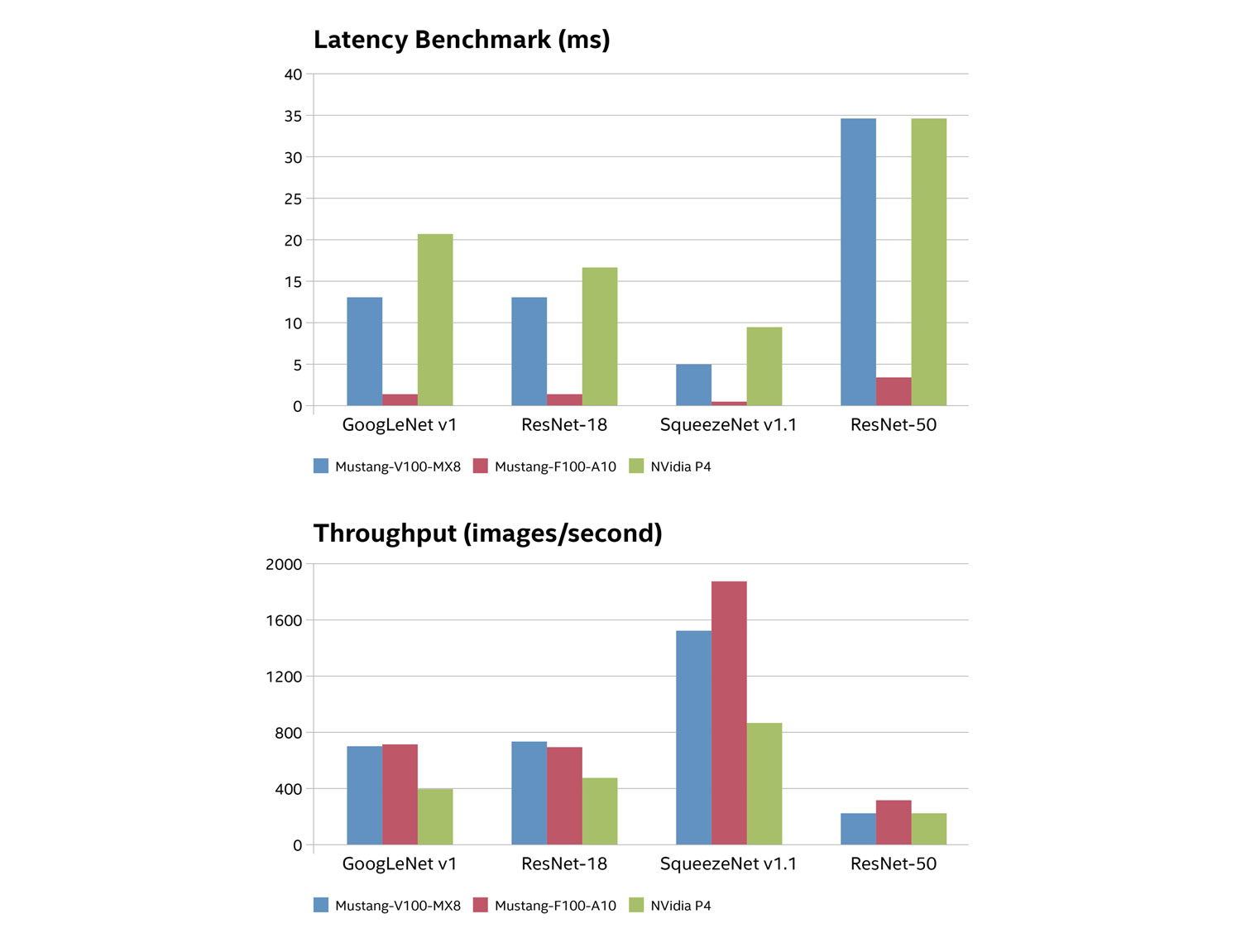
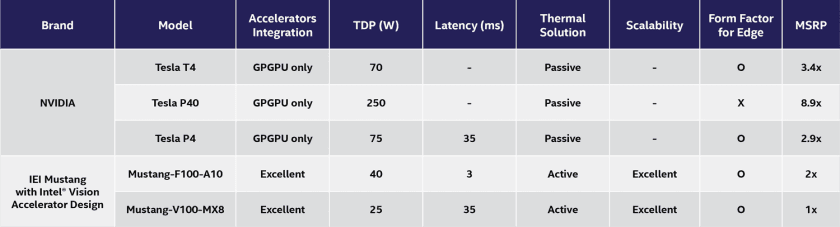
吞吐量和延迟基准性能测试表明,在神经网络工作负载中,FPGA 和 VPU 加速器的性能明显优于 GPU。如图 5 所示,IEI Mustang 产品的热设计功耗 (TDP) 评分和价位要低得多。
基准性能测试探秘
GPU 难以完成这类小批量处理任务的原因与架构有很大关系。
GPU 通常划分为几个模块,统辖 32 个内核,所有这些内核并行执行同一条指令。这种单指令多数据 (SIMD) 架构使 GPU 能够比传统处理器更快地完成大型复杂任务。
但是,延迟与所有这些从内存访问数据的内核关联,在 P4 上是外部 DDR5 SDRAM。在较大的工作负载中,这种延迟被以下事实掩盖了,即并行处理可以通过应用这么多内核的性能来快速弥补这一延迟。在较小的工作负载中,延迟便更加明显。
相比之下,由于 FPGA 和 VPU 架构灵活,在处理较小的工作负载方面则表现出色。
英特尔® Arria® 10 FPGA 内幕
例如,可以重新配置 Arria 10 FPGA 结构以支持不同的逻辑、算术或寄存器函数。而且这些函数可以统合成 FPGA 结构模块,以满足特定神经网络算法的确切要求。
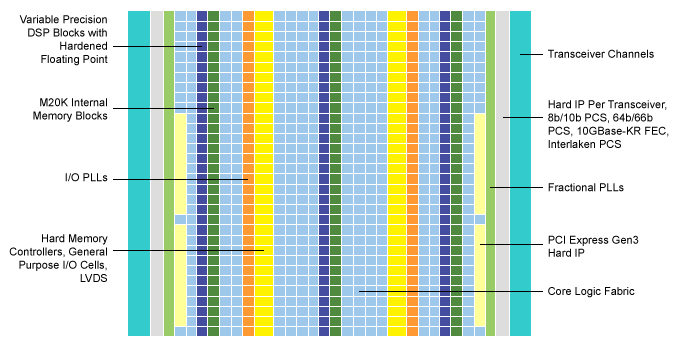
这些器件还集成了具有浮点功能的可变精度 DSP 模块(图 6)。这就提高了 GPU 的并行处理能力,却未增加延迟。
超低延迟通过内存和高带宽内部互连实现,而这些互连则为逻辑块提供直接数据访问。结果,Arria 10 设备可以比 GPU 更快地检索和计算小批量推断数据,从而显著提高吞吐量。
借助英特尔® Movidius™ Myriad™ X VPU 实现灵活的计算和内存
同时,Myriad X VPU 的神经计算引擎提供了专用的片上人工智能加速器。神经计算引擎是一种硬件模块,能够以最小的功耗、每秒 1 万亿次运算 (TOPS) 的速度处理神经网络。
神经计算引擎由前面提到的 16 个可编程 SHAVE 内核提供辅助支持。这些 128 位矢量处理器与映像加速器和硬件编码器结合在一起,可创建高吞吐量的 ISP 管道。实际上,SHAVE 内核可以一次共同运行多个 ISP 管道。
管道中的每个组件都可以访问通用的智能内存结构(图 7)。因此,神经网络工作负载可以在优化的神经计算引擎中终止,不会因多内存访问而增加延迟或功耗。
核对基准
本文展示了芯片架构和硬件加速器的创新如何在边缘实现人工智能。尽管每种架构都有其优点,但至关重要的是要考虑这些平台如何影响神经网络运算和系统作为一个整体的计算性能、功耗和延迟。
为此,请确保在开始接下来的人工智能设计之前核对基准。