机器学习获得 2.2 倍性能提升
机器学习正在使工业自动化发生革命性的变化:协作机器人向人类工人学习制造流程,然后更高效地执行这些流程。 人工智能机器可自我诊断即将发生的组件故障并请求维护。 而这还仅仅是个开始。
当然,类似的应用将需要强大的计算能力。 这使得英特尔® 至强® 可扩展处理器(原代号为“Purley”)的推出成为 AI 的重大里程碑。 每插槽高达 28 个内核以及采用全新英特尔® 高级矢量扩展 512(英特尔® AVX-512)指令,这些芯片相比上一代处理器在深度学习训练和推断方面的性能将提升 2.2 倍。
对于工业服务器而言,全新的网格互联架构、高速缓存内存设计、软件工具以及现成的主板解决方案(加快创建基于 AI 的应用)可以支持下一代的性能。
AVX-512:AI 重负荷设备
从 AI 的角度来看,英特尔® 至强可扩展处理器最重要的新特性是对于英特尔® AVX-512 指令的支持,相比上一代处理器,每周期的浮点运算次数翻倍。 尤其是,SIMD 指令集的新增指令专门用来加快处理 AI 和机器学习应用生成的计算密集型工作负载。
值得一提的是,这一吞吐量的提升并不以增加功耗为代价。 如图 1 所示,英特尔 AVX-512 提供了比以前的 SIMD 扩展高得多的单位功率性能,在同等功耗水平和较低的时钟速度上实现了更高的性能。
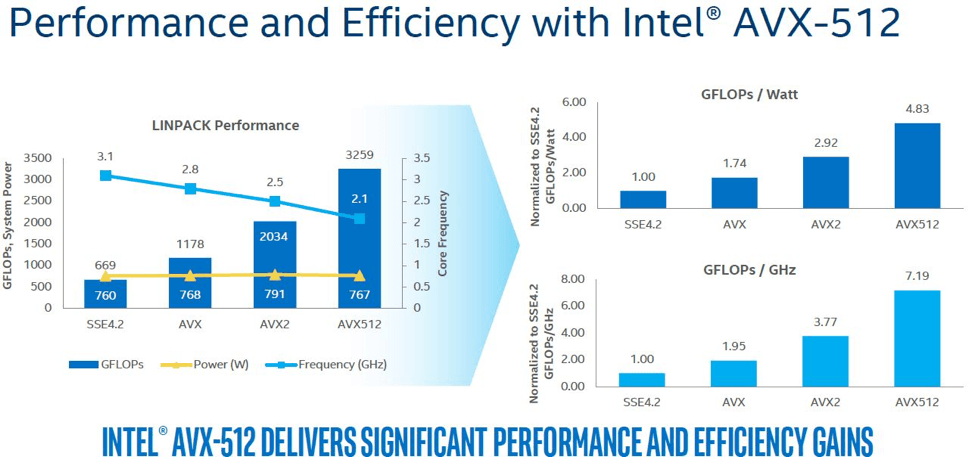
还有一点需要指出,每个处理器内核有两个 512 位融合乘加 (FMA) 单元,使机器学习和 AI 算法最常见的运算之一实现加速。
当然,内核数量多必定有帮助。 新款芯片每个插槽支持高达 28 个内核,相比而言,上一代产品最多支持 24 个内核。
互联和内存技术实现跳跃性发展
为了支持英特尔® 至强® 可扩展处理器的计算能力,Purley 的 L2 高速缓存达到 1 MB,已经是上一代处理器的 256 KB 的四倍。 靠近内核增加更多高速缓存可显著降低内存访问延迟,从而在执行高要求的计算任务(如机器学习、数据压缩和运动跟踪)时显著加快应用响应速度。
英特尔还在新款英特尔® 至强® 可扩展处理器的新型 Skylake-SP 微体系架构中选用了一系列更新的内核架构增强功能。 这些增强功能包括新型片上网格互联架构、升级的插槽间互联技术以及可扩展 I/O。
就内核间的片上连接性而言,全新的高速缓存相干网格互联架构取代了早期的英特尔® 至强® 处理器的环形拓扑技术,降低了工业服务器的通信延迟。 网格架构并非沿着芯片周围的专用通信路径传输内核间通信,而是通过尽可能最短的 X/Y 轴传输数据(图 2)。 这有助于最大限度发挥计算性能来处理需要访问数据或在多个内核上执行的密集工作负荷。
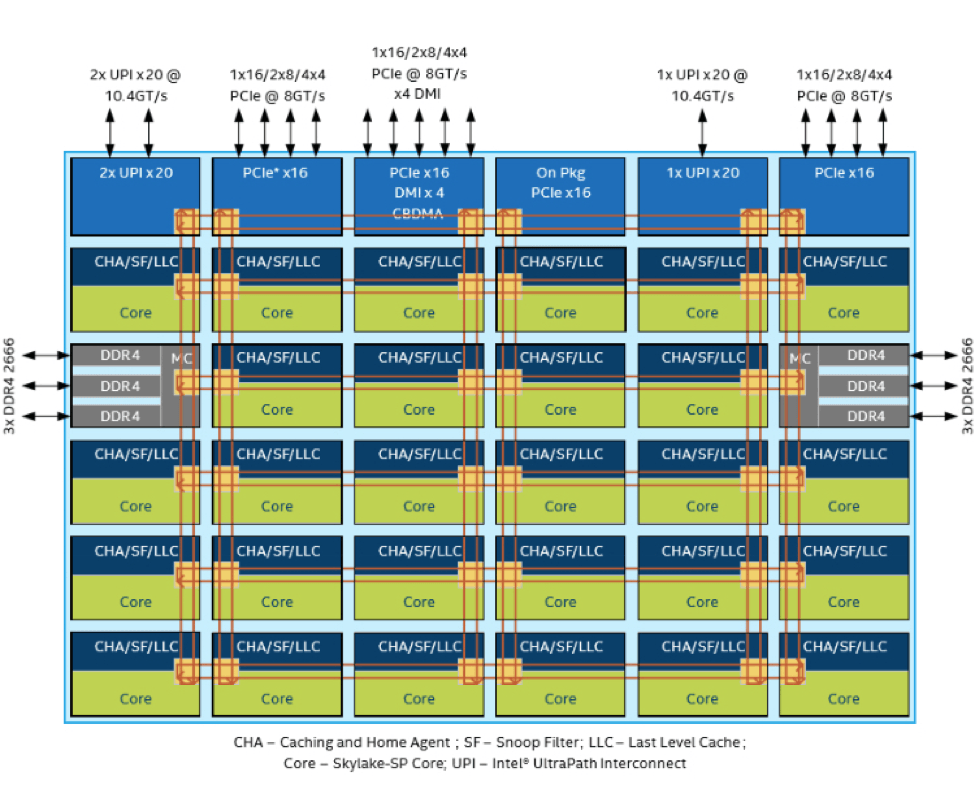
对于要求多插槽性能的工业服务器设计而言,英特尔还改进了快速通道互联 (QPI)。 升级之后的英特尔® 超级通道互联(英特尔® UPI)可以提供 10.4 GTps 的插槽间线路速率,为 AI 训练和推断提供多处理器扩展能力。 每个英特尔® 至强可扩展处理器上有最多三个英特尔® UPI 端口,便于以后轻松扩展多内核工业服务器设计。
此外,新款英特尔® 至强® 处理器支持 48 条 PCIe 3.0 通道、4 个集成的万兆以太网 (GbE) 端口和大量其他高速 I/O。
在现有工业服务器中集成高级功能
关于下一代英特尔® 至强® 处理器为运行机器学习工作负载的工业服务器提供的性能和灵活性,Trenton System 的 SEP8253 HDEC 主机板就是一个例子。 SEP8253 HDEC 主机板采用两个英特尔® 至强® 金牌 6100 系列处理器,此款处理器是英特尔® 至强® 可扩展处理器产品组合的成员之一。
SEP8253 主板是一款插件式网卡,通过将主板上两个处理器的所有 88 条 PCIe 链路向下路由到双密度 PCIe 卡边缘手指,充分发挥出英特尔® 至强® 可扩展处理器的计算和吞吐能力。 PCIe 设计可以轻松将 SEP8253 与各种背板和系统平台集成,包括 2U、4U 和 5U 19 英寸架装式工业服务器(图 3)。

软件增强
各种软件工具、优化库、基础构建模块和灵活的框架可以简化开发人员在英特尔® 至强® 可扩展处理器上构建 AI 功能的工作流程和代码创建。
比如,开发人员可使用英特尔® Parallel Studio XE 软件开发套件实现机器学习和 AI 现有代码库的现代化,以及通过利用英特尔® 至强® 可扩展处理器的新功能提升应用性能。 例如,英特尔® Parallel Studio XE 2017 还包括可在英特尔® 至强® 可扩展处理器上加速深度学习框架处理的性能库,如适用于深度神经网络的英特尔® 数学核心函数库(英特尔® MKL-DNN))。 免版税的英特尔® MKL-DNN 软件可以加速数学处理例程以增强应用性能。
而且,英特尔® 数据分析加速库(英特尔® DAAL)可以加速数据分析。 为了实现深度学习、典型机器学习和数据分析性能,它采用了高度优化的函数,同时,为了实现尽可能最高水平的分析吞吐量,还优化了数据摄取和算法计算(图 4)。
英特尔® 至强® 可扩展® 处理器还针对 Neon、Caffe、Theano、Torch 和 TensorFlow 等常用机器学习框架进行了优化。
强大的可扩展性
英特尔® 至强® 可扩展处理器在企业服务器级处理产品组合方面实现了巨大的架构跨越,支持新一代的工作负载密集型应用,例如工业自动化行业的深度学习。 高度可扩展的产品系列包括经济高效、节能以及高性能的平台,有很多保修 15 年的选项。
自动化工程师:人工智能制造环境的升级途径已经水到渠成。